Automation is a key part of what we do, finding new ways to reduce the time spent on repetitive tasks allows you to spend more time running your business. Recently we have been looking at ways to streamline the receipt tagging process and today we will start beta testing a new receipt analysis tool.
The Receipt Analyser uses Optical Character Recognition (OCR) coupled with Machine Learning (ML) algorithims to detect patterns in receipts and extract key data such as supplier name, date and total amount.

How does it work?
Once enabled the Receipt Analyser adds a small wand icon in the Receipt Hub preview screen.

When you tap this icon the receipt will be submitted for review and in a few seconds any matches will be returned. Currently the Receipt Analyser is optimised to work on thermal till receipts and looks for the following data points.
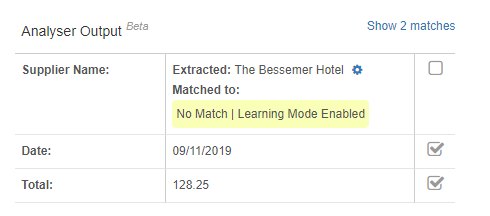
- Supplier name
- Date of purchase
- Total amount
You can show the raw matches by clicking on the link in the top right of the analyser output box. A supplier name match will occur when the supplier name returned exactly matches the name of the supplier already saved on your account. If the text does not precisely match, the analyser will switch to “learning mode” and will record the supplier that you proceed to manually match the receipt to. That way when similar text is extracted in future the analyser will know which supplier to automatically match to.
Receipt Analyser limitations
The Receipt Analyser is based on OCR and Machine Learning and therefore accurate extraction is based on a number of variables.
1. Document type
The Machine Learning module is trained to work with thermal till receipts. Invoices and multi-page documents will see varying degrees of success. The analyser can extract text from images (png, jpg) and PDF files.
2. Image quality
High resolution, high contrast receipts with fewer distortions will make it easier for the OCR process to accurately extract the text from the receipt image. Reduction of background noise and cropping as close as possible to the actual receipt will deliver optimum results.
3. Supplier name matching
The supplier name will look for exact matches, if an exact match is not identified the analyser will record the supplier name to which the user manually matches the receipt and will apply that same rule automatically in future.
Beta programme requirements
Initially we are looking for a relatively small number of participants to test the Receipt Analyser.
If you are routinely processing receipts in QuickFile you can request access to the programme in Help >> Additional Services >> Beta Features and then enter the code " ML0001". This particular feature will require a power user subscription to activate.

 …
…
 but that may not be true for all QuickFiles users.
but that may not be true for all QuickFiles users. . Your scanner did catch the invoice pretty well, the only thing which was wrong was the amount. For the amount I paid your software took your VAT reg. Number. I thought it is maybe interesting for you to know about it. It was not a big thing, I changed the amount and fine.
. Your scanner did catch the invoice pretty well, the only thing which was wrong was the amount. For the amount I paid your software took your VAT reg. Number. I thought it is maybe interesting for you to know about it. It was not a big thing, I changed the amount and fine.